🔌 mcp-servermcp
180.8K
n8n
Fair-code workflow automation platform with native AI capabilities. Combine visual building with custom code, self-host or cloud, 400+ integrations.
Nn8n-io3 months ago
npx n8nFair-code workflow automation platform with native AI capabilities. Combine visual building with custom code, self-host or cloud, 400+ integrations.
npx n8nThe agent harness performance optimization system. Skills, instincts, memory, security, and research-first development for Claude Code, Codex, Opencode, Cursor and beyond.
git clone https://github.com/affaan-m/everything-claude-code.gitAn open-source AI agent that brings the power of Gemini directly into your terminal.
npx @google/gemini-cli![]()

中文版 README | English
🌙 Let Claude Code do research while you sleep. Wake up to find your paper scored, weaknesses identified, experiments run, and narrative rewritten — autonomously.
🪶 Radically lightweight — zero dependencies, zero lock-in. The entire system is plain Markdown files. No framework to learn, no database to maintain, no Docker to configure, no daemon to babysit. Every skill is a single
SKILL.mdreadable by any LLM — swap Claude Code for Codex CLI, OpenClaw, Cursor, Trae, Antigravity, Windsurf, or your own agent and the workflows still work. Fork it, rewrite it, adapt it to your stack.💡 ARIS is a methodology, not a platform. What matters is the research workflow — take it wherever you go. 🌱
·
·
·
· 💬 Join Community ·
Custom Claude Code skills for autonomous ML research workflows. These skills orchestrate cross-model collaboration — Claude Code drives the research while an external LLM (via Codex MCP) acts as a critical reviewer. 🔀 Also supports alternative model combinations (Kimi, LongCat, DeepSeek, etc.) — no Claude or OpenAI API required. For example, MiniMax-M2.7 + GLM-5 or GLM-5 + MiniMax-M2.7. 🤖 Codex CLI native — full skill set also available for OpenAI Codex. 🖱️ Cursor — works in Cursor too. 🖥️ Trae — ByteDance AI IDE. 🚀 Antigravity — Google's agent-first IDE. 🆓 Free tier via ModelScope — zero cost, zero lock-in.
💭 Why not self-play with a single model? Using Claude Code subagents or agent teams for both execution and review is technically possible, but tends to fall into local minima — the same model reviewing its own patterns creates blind spots.
Think of it like adversarial vs. stochastic bandits: a single model self-reviewing is the stochastic case (predictable reward noise), while cross-model review is adversarial (the reviewer actively probes weaknesses the executor didn't anticipate) — and adversarial bandits are fundamentally harder to game.
💭 Why two models, not more? Two is the minimum needed to break self-play blind spots, and 2-player games converge to Nash equilibrium far more efficiently than n-player ones. Adding more reviewers increases API cost and coordination overhead with diminishing returns — the biggest gain is going from 1→2, not 2→4.
Claude Code's strength is fast, fluid execution; Codex (GPT-5.4 xhigh) is slower but more deliberate and rigorous in critique. These complementary styles — speed × rigor — produce better outcomes than either model talking to itself.
These are full pipelines — you can also use each workflow independently. Already have an idea? Skip to Workflow 1.5. Have results? Jump to Workflow 3. Got reviews? Jump to Workflow 4. See Quick Start for all commands and Workflows for the full breakdown.
Basic mode — give ARIS a research direction, it handles everything:
/research-pipeline "factorized gap in discrete diffusion LMs"
🔥 Targeted mode — got a paper you want to improve? Give ARIS the paper + the code:
/research-pipeline "improve method X" — ref paper: https://arxiv.org/abs/2406.04329, base repo: https://github.com/org/project
ARIS reads the paper → finds its weaknesses → clones the codebase → generates ideas that specifically fix those weaknesses with that code → runs experiments → writes your paper. Like telling a research assistant: "read this paper, use this repo, find what's missing, and fix it."
Mix and match:
ref paperonly = "what can be improved?",base repoonly = "what can I build with this code?", both = "improve this paper using this code."
🔥 Rebuttal mode — reviews just dropped? Don't panic. ARIS reads every concern, builds a strategy, and drafts a rebuttal that's grounded, structured, and under the character limit:
/rebuttal "paper/ + reviews" — venue: ICML, character limit: 5000
| Parameter | Default | What it does |
|---|---|---|
venue | ICML | Target venue (ICML/NeurIPS/ICLR/CVPR/ACL/AAAI/ACM) |
character limit | — | Required. Hard character limit for rebuttal text |
quick mode | false | Stop after parsing + strategy (Phase 0-3). See what reviewers want before drafting |
auto experiment | false | Auto-run supplementary experiments via /experiment-bridge when reviewers ask for new evidence |
max stress test rounds | 1 | How many times GPT-5.4 xhigh stress-tests the draft |
max followup rounds | 3 | Per-reviewer follow-up round limit |
Three safety gates — rebuttal will NOT finalize if any fails:
Two outputs: PASTE_READY.txt (exact char count, paste to venue) + REBUTTAL_DRAFT_rich.md (extended version for manual editing).
After acceptance — your paper is in, now prepare the presentation:
/paper-slides "paper/" # → Beamer PDF + PPTX + speaker notes + Q&A prep
/paper-poster "paper/" # → A0/A1 poster PDF + editable PPTX + SVG
💡 From idea to paper to podium — one toolchain. 🌱
| Paper | Score | Venue | Author | Stack |
|---|---|---|---|---|
| CS Paper | 8/10 "clear accept" | CS Conference | @DefanXue & @Monglitay | Claude Code + GPT-5.4 |
| AAAI Paper | 7/10 "good paper, accept" | AAAI 2026 Main Technical | @xinbo820-web | Pure Codex CLI |
🎉 Built entirely with ARIS — from idea to acceptance. Full details + reviewer screenshots →
/rebuttal — post-submission rebuttal pipeline. Parse reviews → atomize → strategy → draft → safety check → GPT-5.4 stress test → finalize (strict + rich versions) → follow-up rounds. 3 safety gates (no fabrication, no overpromise, full coverage). quick mode for analysis only. auto experiment for supplementary experiments. Designed from 5 successful rebuttal case studies + 3 rounds GPT-5.4 xhigh design review/training-check, /result-to-claim, /ablation-planner. 📦 compact mode — generate lean summary files for short-context models and session recovery (— compact: true). 🔄 research-refine checkpoint — auto-resume after interruption. Community contributions by @JingxuanKang & @couragec2026-03-18 — 🎤 paper-slides + 🔁 Codex+Claude bridge + 🖱️ Cursor guide + 🤖 Codex CLI skills + 📝 grant-proposal + 🎨 paper-illustration (Gemini) + 📊 CitationClaw
2026-03-17 — 🔧 Git code sync + 🆓 ModelScope guide + parameter pass-through
2026-03-16 — 🔬 research-refine + experiment-plan — turn vague ideas into problem-anchored proposals with claim-driven experiment roadmaps. Now integrated into Workflow 1 (/idea-discovery). Community contribution by @zjYao36
2026-03-16 — 🇨🇳 Alibaba Coding Plan guide — one API key, 4 models (Kimi-K2.5 + Qwen3.5+ + GLM-5 + MiniMax-M2.5), dual-endpoint setup. Community contribution by @tianhao909
2026-03-15 — 🔀 Bring your own model! Any OpenAI-compatible API now works as reviewer via MCP server. GLM, MiniMax, Kimi, LongCat, DeepSeek all tested —
# 1. Install skills
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git
cp -r Auto-claude-code-research-in-sleep/skills/* ~/.claude/skills/
# 2. Set up Codex MCP (for review skills)
npm install -g @openai/codex
codex setup # set model to gpt-5.4 when prompted
claude mcp add codex -s user -- codex mcp-server
# 3. Use in Claude Code
claude
> /idea-discovery "your research direction" # Workflow 1 — be specific! not "NLP" but "factorized gap in discrete diffusion LMs"
> /experiment-bridge # Workflow 1.5 — have a plan? implement + deploy + collect results
> /auto-review-loop "your paper topic or scope" # Workflow 2: review → fix → re-review overnight
> /paper-writing "NARRATIVE_REPORT.md" # Workflow 3: narrative → polished PDF
> /rebuttal "paper/ + reviews" — venue: ICML # Workflow 4: parse reviews → draft rebuttal → follow-up
> /research-pipeline "your research direction" # Full pipeline: Workflow 1 → 1.5 → 2 → 3 end-to-end
📝 Templates available! See
templates/for ready-to-use input templates for every workflow — research brief (Workflow 1), experiment plan (Workflow 1.5), narrative report (Workflow 3), paper plan (Workflow 3).
Tip: All pipeline behaviors are configurable via inline overrides — append
— key: valueto any command:
Parameter Default What it does AUTO_PROCEEDtrueAuto-continue at idea selection gate. Set falseto manually pick which idea to pursue before committing GPU timehuman checkpointfalsePause after each review round so you can read the score, give custom modification instructions, skip specific fixes, or stop early sourcesallWhich literature sources to search: zotero,obsidian,local,web, orall(comma-separated)arxiv downloadfalseDownload top relevant arXiv PDFs during literature survey. When false, only fetches metadata (title, abstract, authors)DBLP_BIBTEXtrueFetch real BibTeX from DBLP/ instead of LLM-generated entries. Eliminates hallucinated citations. Zero install
Important: Codex MCP uses the model from
~/.codex/config.toml, not from skill files. Make sure it saysmodel = "gpt-5.4"(recommended). Other options:gpt-5.3-codex,gpt-5.2-codex,o3. Runcodex setupor edit the file directly.
Want Codex to execute but Claude Code to review? See
docs/CODEX_CLAUDE_REVIEW_GUIDE.md. That path installs the baseskills/skills-codex/*, then overlaysskills/skills-codex-claude-review/*, and routes review-heavy skills through the localclaude-reviewMCP bridge.
Want Codex to execute but Gemini to review locally? See
docs/CODEX_GEMINI_REVIEW_GUIDE.mdand CN. That path installs the baseskills/skills-codex/*, then overlaysskills/skills-codex-gemini-review/*, and routes the reviewer-aware predefined skills through the localgemini-reviewMCP bridge using direct Gemini API by default.
See full setup guide for details and alternative model combinations if you don't have Claude/OpenAI API.
📊 31 composable skills — mix and match, or chain into full pipelines (/idea-discovery, /auto-review-loop, /paper-writing, /research-pipeline)
🔍 Literature & novelty — multi-source paper search (Zotero + Obsidian + local PDFs + arXiv/Scholar) + cross-model novelty verification
💡 Idea discovery — literature survey → brainstorm 8-12 ideas → novelty check → GPU pilot experiments → ranked report
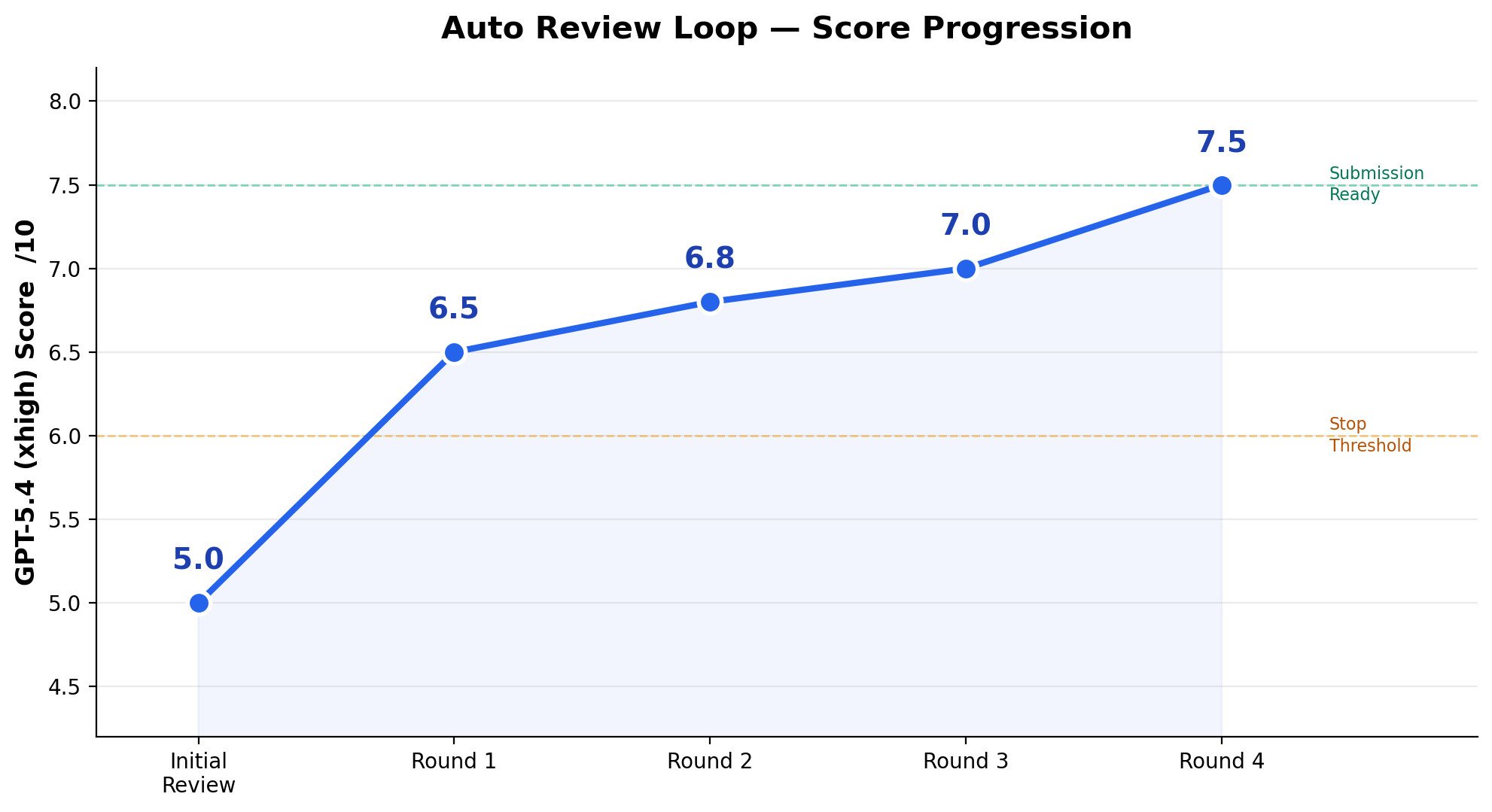
🔄 Auto review loop — 4-round autonomous review, 5/10 → 7.5/10 overnight with 20+ GPU experiments
📝 Paper writing — narrative → outline → figures → LaTeX → PDF → auto-review (4/10 → 8.5/10), one command. Anti-hallucination citations via DBLP/CrossRef
🤖 Cross-model collaboration — Claude Code executes, GPT-5.4 xhigh reviews. Adversarial, not self-play
📝 Peer review — review others' papers as a conference reviewer, with structured scoring and meta-review
🖥️ Review-driven experiments — when GPT-5.4 says "run an ablation", Claude Code automatically writes the script, rsyncs to your GPU server, launches in screen, collects results, and folds them back into the paper. Just configure your server in CLAUDE.md (setup guide)
A real overnight 4-round run on an ML research project, from borderline reject to submission-ready:
| Round | Score | What Happened |
|---|---|---|
| Initial | 5.0/10 | Borderline reject |
| Round 1 | 6.5/10 | Added standard metrics, discovered metric decoupling |
| Round 2 | 6.8/10 | Key claim failed to reproduce, pivoted narrative |
| Round 3 | 7.0/10 | Large seed study killed main improvement claim |
| Round 4 | 7.5/10 ✅ | Diagnostic evidence solidified, submission ready |
The loop autonomously ran 20+ GPU experiments, rewrote the paper's narrative framing, and killed claims that didn't hold up — all without human intervention.
Real projects where the ARIS pipeline was used end-to-end. If you've used ARIS to complete a paper, we'd love to feature it here — open an issue or PR!
| Paper | Rating | Venue | Built by | Notes |
|---|---|---|---|---|
| CS Paper | 8/10 — "Top 50% of accepted papers, clear accept" | CS Conference | @DefanXue & @Monglitay | Full ARIS pipeline: idea → experiments → auto-review → paper writing. Reviewer: "empirical findings are stark, well-supported, and expose a fundamental flaw" |
| AAAI 2026 Paper | 7/10 — "Good paper, accept" | AAAI 2026 Main Technical | @xinbo820-web | Pure Codex CLI (ARIS-Codex skills). Accepted at AAAI 2026 |
🎉 Papers built entirely with ARIS — from idea to acceptance. Know more? Let us know!
Domain-specific skills and external projects contributed by the community. PRs welcome — just add a skills/your-skill/SKILL.md and open a PR!
💡 How to use: Community skills are not auto-wired into core workflows. To use one, ask your executor (Claude Code / OpenClaw / etc.) to read the skill's
SKILL.md, then plug it into the appropriate workflow stage based on the description below.
🎉 Community Skills (12): research-refine · experiment-plan · grant-proposal · paper-poster · paper-slides · mermaid-diagram · proof-writer · comm-lit-review · dse-loop · idea-discovery-robot · formula-derivation ·
🌐 External Projects & Docs (9): open-source-hardening-skills · CitationClaw · auto-hparam-tuning · Antigravity Adaptation Guide · OpenClaw Adaptation Guide · Cursor Adaptation Guide · Codex+Claude Review Bridge · Trae Adaptation Guide · paper-illustration
🙌 Thanks to every contributor! We fold the tables below to keep the README readable — but every skill and project here is equally valued. PRs always welcome!
| Name | Domain | Description | Codex MCP? |
|---|---|---|---|
🔬 research-refine | General | Turn a vague idea into a problem-anchored, implementation-oriented method proposal. Best inserted between /idea-discovery and /auto-review-loop | Yes |
🧪 experiment-plan | General | Turn a refined proposal into a claim-driven experiment roadmap with ablations, budgets, and run order | No |
🧭 research-refine-pipeline | General | One-shot chain: /research-refine → /experiment-plan for method refinement plus experiment planning | Yes |
📝 grant-proposal | General | Grant proposal drafting (KAKENHI/NSF/NSFC/ERC/DFG/SNSF/ARC/NWO). Chains /research-lit → /novelty-check → → |
| Name | Domain | Description |
|---|---|---|
| 🛡️ open-source-hardening-skills | DevOps / OSS | 10-skill pipeline to harden research code into production-ready open-source projects — audit, refactor, test, CI, docs, review |
| 📊 CitationClaw | General | Citation impact analysis — input paper title → citation crawling, scholar identification, tiered analysis, HTML dashboard |
| 🚀 Antigravity Adaptation Guide | General | Use ARIS skills in Google Antigravity — native SKILL.md support, dual model (Claude Opus 4.6 / Gemini 3.1 Pro), MCP setup, EN + CN guides |
| 🐾 OpenClaw Adaptation Guide | General | Use ARIS workflow methodology in OpenClaw — skill-to-stage mapping, file-based orchestration, no Claude Code CLI needed |
| 🖱️ Cursor Adaptation Guide | General |
These skills compose into a full research lifecycle. The four workflows can be used independently or chained together:
/idea-discovery/experiment-bridge/auto-review-loop/paper-writing (or step by step: /paper-plan → /paper-figure → /paper-write → /paper-compile → /auto-paper-improvement-loop)/rebuttal — parse reviews, draft safe rebuttal, follow-up rounds/research-pipeline + /rebuttal — from idea to acceptance⚠️ Important: These tools accelerate research, but they don't replace your own critical thinking. Always review generated ideas with your domain expertise, question the assumptions, and make the final call yourself. The best research comes from human insight + AI execution, not full autopilot.
/research-lit → /idea-creator → /novelty-check → /research-refine → /experiment-bridge → /auto-review-loop → /paper-writing → submit → /rebuttal → accept! 🎉
(survey) (brainstorm) (verify novel) (refine method) (implement+deploy) (review & fix) (write paper) (send) (reply to reviewers)
├────────────── Workflow 1: Idea Discovery ──────────────┤ ├ Workflow 1.5 ─┤ ├── Workflow 2 ──┤ ├── Workflow 3 ──┤ ├── Workflow 4 ──┤
📝 Blog post: 梦中科研全流程开源
"What's the state of the art? Where are the gaps? How do we solve it?"
Don't have a concrete idea yet? Just give a research direction — /idea-discovery handles the rest:
The output is a ranked IDEA_REPORT.md plus a refined proposal (refine-logs/FINAL_PROPOSAL.md) and experiment plan (refine-logs/EXPERIMENT_PLAN.md) for the top idea. Dead-end ideas are documented too, saving future exploration.
┌─────────────────────────────────────────────────────────────────┐
│ Idea Discovery & Method Refinement │
│ │
│ /research-lit /idea-creator /novelty-check │
│ (find papers) (brainstorm) (verify novelty) │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Scan │───▶│ Generate │────▶│ Check if │ │
│ │ local │ │ 8-12 │ │ idea is │ │
│ │ papers + │ │ ideas │ │ novel │ │
│ │ search │ │ + rank │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ │
│ │ Filter │────▶│ External │ │
│ │ by cost, │ │ LLM │ │
│ │ novelty │ │ evaluates│ │
│ └──────────┘ └──────────┘ │
│ │ │
│ /research-refine ▼ │
│ (refine method) ┌──────────┐ │
│ │ │ Freeze │ │
│ ▼ │ problem │ │
│ ┌──────────┐ │ anchor + │ │
│ │ Iterate │◀───▶│ refine │ │
│ │ until │ │ method │ │
│ │ score≥9 │ └──────────┘ │
│ └──────────┘ │ │
│ │ ▼ │
│ /experiment-plan ┌──────────┐ │
│ │ │ Claim- │ │
│ ▼ │ driven │ │
│ ┌──────────┐ │ experiment│ │
│ │ Plan │────▶│ roadmap │ │
│ │ runs │ └──────────┘ │
│ └──────────┘ │
│ │
│ Typical flow: │
│ 1. /research-lit "discrete diffusion models" │
│ 2. /idea-creator "DLLMs post training" │
│ 3. Review ranked ideas, pick top 2-3 │
│ 4. /novelty-check "top idea" (deep verification) │
│ 5. /research-review "top idea" (critical feedback) │
│ 6. /research-refine "top idea" (problem anchor + method) │
│ 7. /experiment-plan (claim-driven roadmap) │
│ 8. /run-experiment → /auto-review-loop │
└─────────────────────────────────────────────────────────────────┘
Skills involved: research-lit + idea-creator + novelty-check + research-review + research-refine-pipeline
💡 One-command shortcut:
/idea-discovery "your research direction"runs this entire workflow automatically.
🔄 Human-in-the-loop: Each phase presents results and waits for your feedback. Not happy? Tell it what's missing — it refines the prompt and regenerates. Trust the defaults? It auto-proceeds with the top-ranked option. You decide how hands-on to be.
⚙️ Pilot experiment budgets (max hours, timeout, GPU budget) are configurable — see Customization.
📝 Blog post: Claude Code 两月 NeurIPS 指北
"I have a plan. Now implement it, deploy it, and get me initial results."
Already have an experiment plan (from Workflow 1 or your own)? /experiment-bridge turns it into running code:
refine-logs/EXPERIMENT_PLAN.md)code review: true by default)/run-experiment┌─────────────────────────────────────────────────────────────────┐
│ Workflow 1.5: Experiment Bridge │
│ │
│ EXPERIMENT_PLAN.md │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Claude │────▶│ GPT-5.4 │────▶│ Sanity │ │
│ │ Code │ │ xhigh │ │ Check │ │
│ │ writes │ │ reviews │ │ (1 GPU) │ │
│ │ code │ │ code │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Collect │◀────│ Monitor │◀────│ Deploy │ │
│ │ results │ │ progress │ │ to GPUs │ │
│ │ │ │ (+ W&B) │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ Ready for /auto-review-loop │
└─────────────────────────────────────────────────────────────────┘
Skills involved: experiment-bridge + run-experiment + monitor-experiment
💡 One-command shortcut:
/experiment-bridgereadsrefine-logs/EXPERIMENT_PLAN.mdautomatically. Or point it to any plan:/experiment-bridge "my_plan.md".
⚙️
CODE_REVIEW,AUTO_DEPLOY,SANITY_FIRST,MAX_PARALLEL_RUNSare configurable — see Customization.
"Review my paper, fix what's wrong, repeat until it's good."
GPT-5.4 reviews → identifies weaknesses → suggests experiments → Claude Code writes scripts, deploys to GPU, monitors results, rewrites the paper — all while you sleep. Just add your GPU server config to
CLAUDE.md.
┌─────────────────────────────────────────────────────────────┐
│ Auto Review Loop │
│ │
│ /research-review /auto-review-loop │
│ (single deep review) (autonomous loop) │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ External │──▶│ Implement│──▶│ Monitor │──▶ repeat │
│ │ LLM │ │ fixes │ │ results │ until │
│ │ reviews │ │ & run │ │ │ score ≥ 6 │
│ └──────────┘ │ experiments│ └──────────┘ │
│ └──────────┘ │
│ │
│ When reviewer suggests a new method direction: │
│ /novelty-check — verify idea isn't already published │
│ │
│ Supporting skills: │
│ /run-experiment — deploy to local/remote GPU │
│ /analyze-results — interpret experiment outputs │
│ /monitor-experiment — check progress, collect results │
└─────────────────────────────────────────────────────────────┘
Skills involved: auto-review-loop + research-review + novelty-check + run-experiment + analyze-results + monitor-experiment
💡 One-command shortcut:
/auto-review-loop "your paper topic"runs this entire workflow automatically.What to pass as argument? A short topic or scope is enough — the skill automatically reads your project's narrative docs (
NARRATIVE_REPORT.md), memory files, experiment results, and prior reviews to build the full context for GPT-5.4. Examples:
/auto-review-loop "factorized gap in discrete diffusion LMs"— broad topic, skill finds everything/auto-review-loop "focus on Section 3-5, our CRF results are weak"— targeted scope with hints/auto-review-loop— also works: skill reads project files and infers the topic
🛡️ Key safety features:
REVIEW_STATE.json) after each round. If the context window fills up and auto-compacts mid-loop, the workflow reads the state file and resumes from where it left off — no human intervention needed⚙️ MAX_ROUNDS, score threshold, and GPU limits are configurable — see Customization.
📝 Blog post: 开源 | 睡觉 Claude 自动跑实验改文
"Turn my research narrative into a submission-ready PDF." Requires a local LaTeX environment — see Prerequisites.
┌─────────────────────────────────────────────────────────────┐
│ Paper Writing Pipeline │
│ │
│ /paper-plan /paper-figure /paper-write │
│ (outline) (plots & tables) (LaTeX draft) │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Claims- │───▶│ Generate │────▶│ Section │──┐ │
│ │ Evidence │ │ figures, │ │ by │ │ │
│ │ Matrix + │ │ tables, │ │ section │ │ │
│ │ Section │ │ LaTeX │ │ LaTeX │ │ │
│ │ Plan │ │ includes │ │ draft │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │ │
│ │ │ │
│ │ /paper-compile │ │
│ │ (build PDF) │ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ NARRATIVE_REPORT.md ──► PAPER_PLAN.md ──► paper/ │ │
│ │ (input) (outline) (LaTeX+PDF)│ │
│ └──────────────────────────────────────────────────┘ │
│ │
│ Typical flow: │
│ 1. Write NARRATIVE_REPORT.md (from Workflow 2 results) │
│ 2. /paper-plan (claims-evidence matrix + section plan) │
│ 3. /paper-figure (comparison tables, training curves, etc.) │
│ 4. /paper-write (section-by-section LaTeX generation) │
│ 5. /paper-compile (build PDF, fix errors, page check) │
│ 6. /auto-paper-improvement-loop (review ×2 + format check) │
└─────────────────────────────────────────────────────────────┘
Skills involved: paper-plan + paper-figure + paper-write + paper-compile + auto-paper-improvement-loop + (post-acceptance) paper-poster + paper-slides
One-command shortcut:
/paper-writing "NARRATIVE_REPORT.md"runs this entire workflow automatically.
Input: A NARRATIVE_REPORT.md describing the research: claims, experiments, results, figures. The more detailed the narrative (especially figure descriptions and quantitative results), the better the output. See templates/NARRATIVE_REPORT_TEMPLATE.md for a complete example.
Output: A submission-ready paper/ directory with LaTeX source, clean .bib (only cited entries), and compiled PDF.
Key features:
pdftotext-based precise check that main body fits page limit⚠️ Figure generation scope:
/paper-figureauto-generates data-driven plots (training curves, bar charts, heatmaps) and comparison tables from JSON/CSV. For architecture diagrams and method figures:illustration: gemini(default) uses Claude→Gemini→Nano Banana Pro for publication-quality diagrams;illustration: mermaidgenerates Mermaid diagrams for free;illustration: falseskips AI figures entirely.Gemini API setup (for
illustration: gemini): Get your API key at Google AI Studio, then set it as an environment variable:export GEMINI_API_KEY="your-key". Or add to your shell profile (~/.zshrc/~/.bashrc). No other dependencies needed.
Tested end-to-end: Generated a 9-page ICLR 2026 theory paper (7 sections, 29 citations, 4 figures, 2 comparison tables) from a single NARRATIVE_REPORT.md — zero compilation errors, zero undefined references.
After Workflow 3 generates the paper, /auto-paper-improvement-loop runs 2 rounds of GPT-5.4 xhigh content review → fix → recompile, plus a final format compliance check, autonomously polishing the paper from rough draft to submission-ready.
Score Progression (Real Test — ICLR 2026 theory paper):
| Round | Score | Key Changes |
|---|---|---|
| Round 0 | 4/10 (content) | Baseline |
| Round 1 | 6/10 (content) | Fixed assumptions, softened claims, renamed notation |
| Round 2 | 7/10 (content) | Added synthetic validation, stronger limitations |
| Round 3 | 5→8.5/10 (format) | Removed hero fig, appendix, compressed conclusion, float spacing |
Final: 8 pages main body (ICLR limit: 9), 0 overfull hbox, ICLR-compliant. +4.5 points across 3 rounds.
\resizebox\captionsetup, \textfloatsep)itemize environments"Reviews are in. Help me draft a safe, grounded rebuttal."
Got reviews back? /rebuttal parses them, builds a strategy, and drafts a venue-compliant response:
auto experiment: true, auto-run supplementary experiments via /experiment-bridgePASTE_READY.txt (exact character count) + REBUTTAL_DRAFT_rich.md (extended version for manual editing)┌─────────────────────────────────────────────────────────────────┐
│ Workflow 4: Rebuttal │
│ │
│ Reviews arrive │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Parse & │────▶│ Strategy │────▶│ Evidence │ │
│ │ atomize │ │ plan │ │ sprint │ │
│ │ reviews │ │ │ │ (optional)│ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Finalize │◀────│ GPT-5.4 │◀────│ Draft │ │
│ │ 2 versions│ │ stress │ │ rebuttal │ │
│ │ │ │ test │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ PASTE_READY.txt (strict) + RICH.md (extended) │
│ │ │
│ ▼ │
│ Follow-up rounds (delta replies, per-reviewer threads) │
└─────────────────────────────────────────────────────────────────┘
Skills involved: rebuttal
💡 Quick mode:
/rebuttal — quick mode: truestops after parsing + strategy (Phase 0-3). See what reviewers want before committing to a full draft.
⚙️
VENUE,AUTO_EXPERIMENT,QUICK_MODE,MAX_STRESS_TEST_ROUNDSare configurable — see Customization.
Three safety gates — rebuttal will NOT finalize if any fails:
| Skill | Description | Codex MCP? |
|---|---|---|
🏗️ research-pipeline | End-to-end: Workflow 1 → 1.5 → 2 → 3, from research direction to submission | Yes |
| Skill | Description | Codex MCP? |
|---|---|---|
🔭 idea-discovery | Pipeline orchestrator — runs all skills below in sequence | Yes |
├ 📚 research-lit | Multi-source literature search (Zotero + Obsidian + local PDFs + arXiv API + web) | No |
├ 💡 idea-creator | Brainstorm 8-12 ideas, filter by feasibility, pilot on GPU, rank by signal | Yes |
├ 🔍 novelty-check | Verify idea novelty against recent literature (multi-source + GPT-5.4 cross-check) | Yes |
├ 🔬 research-review |
| Skill | Description | Codex MCP? |
|---|---|---|
🔗 experiment-bridge | Read experiment plan → implement code → sanity check → deploy to GPU → collect initial results | No |
├ 🚀 run-experiment | Deploy experiments to local (MPS/CUDA) or remote GPU servers | No |
└ 👀 monitor-experiment | Monitor running experiments, check progress, collect results | No |
| Skill | Description | Codex MCP? |
|---|---|---|
🔁 auto-review-loop | Pipeline orchestrator — autonomous review→fix→re-review (max 4 rounds) | Yes |
├ 🔬 research-review | Deep review from external LLM (shared with Workflow 1) | Yes |
├ 🔍 novelty-check | Verify novelty when reviewer suggests new directions | Yes |
├ 🚀 run-experiment | Deploy experiments to local (MPS/CUDA) or remote GPU servers | No |
├ 📊 analyze-results | Analyze experiment results, compute statistics, generate insights | No |
└ 👀 monitor-experiment |
| Skill | Description | Codex MCP? |
|---|---|---|
📝 paper-writing | Pipeline orchestrator — runs all skills below in sequence | Yes |
├ 📐 paper-plan | Claims-evidence matrix, section structure, figure plan, citation scaffolding | Yes |
├ 📊 paper-figure | Publication-quality matplotlib/seaborn plots + LaTeX comparison tables | Optional |
├ 🎨 paper-illustration | AI-generated architecture diagrams and method figures via Gemini (when illustration: true) | No (needs Gemini API) |
├ ✍️ paper-write | Section-by-section LaTeX generation (ICLR/NeurIPS/ICML). Anti-hallucination BibTeX via DBLP/CrossRef |
| Skill | Description | Codex MCP? |
|---|---|---|
📝 rebuttal | Parse reviews → atomize → strategy → draft → safety check → stress test → finalize (2 versions) → follow-up | Yes |
| Skill | Description | Codex MCP? |
|---|---|---|
📄 arxiv | Search, download, and summarize arXiv papers. Standalone or /research-lit supplement | No |
🎨 pixel-art | Generate pixel art SVG illustrations for READMEs, docs, or slides | No |
📱 feishu-notify | Feishu/Lark push (webhook) or interactive (bidirectional). Off by default | No |
npm install -g @openai/codex
claude mcp add codex -s user -- codex mcp-server
latexmk and pdfinfo:
# macOS
brew install --cask mactex # or: brew install basictex
brew install poppler # provides pdfinfo
# Ubuntu/Debian
sudo apt install texlive-full latexmk poppler-utils
# Verify
latexmk --version && pdfinfo -v
If you only need Workflow 1 & 2 (idea discovery + auto review), LaTeX is not required.
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git
cd Auto-claude-code-research-in-sleep
# Install all skills globally
cp -r skills/* ~/.claude/skills/
# Or install specific skills
cp -r skills/auto-review-loop ~/.claude/skills/
cp -r skills/research-lit ~/.claude/skills/
cd Auto-claude-code-research-in-sleep
git pull
# Option A: Full update (overwrites all skills with latest version)
cp -r skills/* ~/.claude/skills/
# Option B: Safe update (only add NEW skills, keep your customizations)
cp -rn skills/* ~/.claude/skills/
# Option C: Update specific skills only
cp -r skills/experiment-bridge ~/.claude/skills/
💡 Which option? Use A if you haven't customized any skills. Use B if you've modified skills locally (new skills get added, your changes are preserved — but you'll miss upstream bug fixes in modified files). Use C to selectively update.
# Workflow 1: Idea Discovery
> /idea-discovery "your research direction" # full pipeline
> /research-lit "topic" # just literature survey (all sources)
> /research-lit "topic" — sources: zotero, web # mix and match sources
> /research-lit "topic" — arxiv download: true # also download top arXiv PDFs
> /arxiv "discrete diffusion" — download # standalone arXiv search + download
> /idea-creator "topic" # just brainstorm
# Workflow 2: Auto Research Loop
> /auto-review-loop "your paper topic" # review → fix → repeat
> /research-review "your paper" # single deep review
# Workflow 3: Paper Writing
> /paper-writing "NARRATIVE_REPORT.md" # full pipeline
> /paper-plan "NARRATIVE_REPORT.md" # just outline
> /paper-compile "paper/" # just compile
# Full Pipeline
> /research-pipeline "your research direction" # Workflow 1 → 2 → 3 end-to-end
# Supporting Skills
> /run-experiment train.py --lr 1e-4 --epochs 100
> /analyze-results figures/*.json
> /monitor-experiment server5
To run the auto-review loop without clicking permission prompts, add to .claude/settings.local.json:
{
"permissions": {
"allow": [
"mcp__codex__codex",
"mcp__codex__codex-reply",
"Write",
"Edit",
"Skill(auto-review-loop)"
]
}
}
When GPT-5.4 says "run an ablation study" or "add a baseline comparison", Claude Code automatically writes the experiment script and deploys it to your GPU server. For this to work, Claude Code needs to know your server environment.
Add your server info to your project's CLAUDE.md:
## Remote Server
- SSH: `ssh my-gpu-server` (key-based auth, no password)
- GPU: 4x A100
- Conda env: `research` (Python 3.10 + PyTorch)
- Activate: `eval "$(/opt/conda/bin/conda shell.bash hook)" && conda activate research`
- Code directory: `/home/user/experiments/`
- Use `screen` for background jobs: `screen -dmS exp0 bash -c '...'`
Claude Code reads this and knows how to SSH in, activate the environment, and launch experiments. GPT-5.4 (the reviewer) only decides what experiments to run — Claude Code figures out how based on your CLAUDE.md.
If you are already on the GPU server, you can add the following to your CLAUDE.md:
## GPU Environment
- This machine has direct GPU access (no SSH needed)
- GPU: 4x A100 80GB
- Experiment environment: `YOUR_CONDA_ENV` (Python 3.x + PyTorch)
- Activate before any Python command: `The command to activate your experiment environment` (uv, conda, etc.)
- Code directory: `/home/YOUR_USERNAME/YOUR_CODE_DIRECTORY/`
No server? The review and rewriting skills still work without GPU access. Only experiment-related fixes will be skipped (flagged for manual follow-up).
If you use Zotero to manage your paper library, /research-lit can search your collections, read your annotations/highlights, and export BibTeX — all before searching the web.
Recommended: zotero-mcp (1.8k⭐, semantic search, PDF annotations, BibTeX export)
# Install
uv tool install zotero-mcp-server # or: pip install zotero-mcp-server
# Add to Claude Code (Local API — requires Zotero desktop running)
claude mcp add zotero -s user -- zotero-mcp -e ZOTERO_LOCAL=true
# Or use Web API (works without Zotero running)
claude mcp add zotero -s user -- zotero-mcp \
-e ZOTERO_API_KEY=your_key -e ZOTERO_USER_ID=your_id
Get your API key at https://www.zotero.org/settings/keys
What it enables in /research-lit:
Not using Zotero? No problem — /research-lit automatically skips Zotero and uses local PDFs + web search instead.
If you use Obsidian for research notes, /research-lit can search your vault for paper summaries, tagged references, and your own insights.
Recommended: mcpvault (760⭐, no Obsidian app needed, 14 tools, BM25 search)
# Add to Claude Code (point to your vault path)
claude mcp add obsidian-vault -s user -- npx @bitbonsai/mcpvault@latest /path/to/your/vault
Optional complement: obsidian-skills (13.6k⭐, by Obsidian CEO) — teaches Claude to understand Obsidian-specific Markdown (wikilinks, callouts, properties). Copy to your vault:
git clone https://github.com/kepano/obsidian-skills.git
cp -r obsidian-skills/.claude /path/to/your/vault/
What it enables in /research-lit:
#paper-review, #diffusion-models)Not using Obsidian? No problem — /research-lit automatically skips Obsidian and works as before.
💡 Zotero + Obsidian together: Many researchers use Zotero for paper storage and Obsidian for notes. Both integrations work simultaneously —
/research-litchecks Zotero first (raw papers + annotations), then Obsidian (your processed notes), then local PDFs, then web search.
/research-lit automatically queries the arXiv API for structured metadata (title, abstract, full author list, categories) — richer than web search snippets. No setup required.
By default, only metadata is fetched (no files downloaded). To also download the most relevant PDFs:
/research-lit "topic" — arxiv download: true # download top 5 PDFs
/research-lit "topic" — arxiv download: true, max download: 10 # download up to 10
For standalone arXiv access, use the dedicated /arxiv skill:
/arxiv "attention mechanism" # search
/arxiv "2301.07041" — download # download specific paper
Get mobile notifications when experiments finish, reviews score, or checkpoints need your input — without sitting in front of the terminal.
| Push Only (group cards) | Interactive (private chat) |
|---|---|
Three modes — you choose per-project:
| Mode | What happens | You need |
|---|---|---|
| Off (default) | Nothing. Pure CLI, no Feishu | Nothing |
| Push only | Webhook notifications at key events. Mobile push, no reply | Feishu bot webhook URL |
| Interactive | Full bidirectional. Approve/reject ideas, reply to checkpoints from Feishu | feishu-claude-code running |
Group notifications with rich cards — experiment done, review scored, pipeline complete. Mobile push, no reply needed.
Step 1: Create a Feishu group bot
ARIS Notifications), copy the Webhook URLARIS (all notifications include this word), or leave unrestrictedStep 2: Create config file
cat > ~/.claude/feishu.json << 'EOF'
{
"mode": "push",
"webhook_url": "https://open.feishu.cn/open-apis/bot/v2/hook/YOUR_WEBHOOK_ID"
}
EOF
Step 3: Test it
curl -s -X POST "YOUR_WEBHOOK_URL" \
-H "Content-Type: application/json" \
-d '{
"msg_type": "interactive",
"card": {
"header": {"title": {"tag": "plain_text", "content": "🧪 ARIS Test"}, "template": "blue"},
"elements": [{"tag": "markdown", "content": "Push mode working! 🎉"}]
}
}'
You should see a blue card in your group. Skills will now automatically send rich cards at key events:
| Event | Card color | Content |
|---|---|---|
| Review scored ≥ 6 | 🟢 Green | Score, verdict, top weaknesses |
| Review scored < 6 | 🟠 Orange | Score, verdict, action items |
| Experiment complete | 🟢 Green | Results table, delta vs baseline |
| Checkpoint waiting | 🟡 Yellow | Question, options, context |
| Error | 🔴 Red | Error message, suggested fix |
| Pipeline done | 🟣 Purple | Score progression, deliverables |
Everything Push mode does, plus bidirectional private chat with Claude Code via Feishu. Approve/reject ideas, reply to checkpoints, give custom instructions — all from your phone.
How it works: Push cards go to the group (everyone sees status). Interactive conversations happen in private chat with the bot (you reply, Claude Code acts on it).
Step 1: Complete Push setup above first (you'll keep both)
Step 2: Create a Feishu app on open.feishu.cn
ARIS Claude Bot) → create| Permission | Scope | Why |
|---|---|---|
im:message | Send & receive messages | Core messaging |
im:message:send_as_bot | Send as bot | Bot replies |
im:message.group_at_msg:readonly | Receive group @mentions | Group messages |
im:message.p2p_msg:readonly | Receive private messages | ⚠️ Easy to miss! Without this, the bot connects but never receives your messages |
im:resource | Access attachments | Images/files |
im.message.receive_v1 → save⚠️ Important: The "Long Connection" page may show "未检测到应用连接信息" — this is normal. You need to start the bridge first (Step 3), then come back and save.
For personal/test Feishu organizations, approval is usually instant.
Step 3: Deploy the bridge
git clone https://github.com/joewongjc/feishu-claude-code.git
cd feishu-claude-code
python3 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
# Configure
cp .env.example .env
Edit .env:
FEISHU_APP_ID=cli_your_app_id # From app credentials page
FEISHU_APP_SECRET=your_app_secret # From app credentials page
DEFAULT_MODEL=claude-opus-4-6 # ⚠️ Default is sonnet — change to opus for best results
DEFAULT_CWD=/path/to/your/project # Working directory for Claude Code
PERMISSION_MODE=bypassPermissions # Or "default" for safer mode
⚠️ Model matters: The default
claude-sonnet-4-6works but may struggle with complex project context.claude-opus-4-6correctly identified 18 ARIS skills on first try where sonnet could not.
Start the bridge:
python main.py
# Expected output:
# ✅ 连接飞书 WebSocket 长连接(自动重连)...
# [Lark] connected to wss://msg-frontier.feishu.cn/ws/v2?...
For long-running use, put it in a screen session:
screen -dmS feishu-bridge bash -c 'cd /path/to/feishu-claude-code && source .venv/bin/activate && python main.py'
Step 4: Save event config — Go back to Feishu Open Platform → Events & Callbacks → the long connection should now show "已检测到连接" → Save
If you published the app version before the bridge was running, you may need to create a new version (e.g., 1.0.1) and re-publish after saving event config.
Step 5: Test private chat
你好If the bot doesn't reply: Send /new to reset the session, then try again. Common issues:
| Symptom | Cause | Fix |
|---|---|---|
| Bot connects but never receives messages | Missing im:message.p2p_msg:readonly permission | Add permission → create new version → publish |
| Bot replies but doesn't know your project | DEFAULT_CWD points to wrong directory | Edit .env → restart bridge |
| Bot replies but seems less capable | Using claude-sonnet-4-6 | Change to claude-opus-4-6 in .env → restart |
| Old session has stale context | Session cached from before config change | Send /new in chat to start fresh session |
| "未检测到应用连接信息" when saving events | Bridge not running yet | Start bridge first, then save event config |
Step 6: Update ARIS config
cat > ~/.claude/feishu.json << 'EOF'
{
"mode": "interactive",
"webhook_url": "https://open.feishu.cn/open-apis/bot/v2/hook/YOUR_WEBHOOK_ID",
"interactive": {
"bridge_url": "http://localhost:5000",
"timeout_seconds": 300
}
}
EOF
Now skills will:
| Skill | Events | Push | Interactive |
|---|---|---|---|
/auto-review-loop | Review scored (each round), loop complete | Score + verdict | + wait for continue/stop |
/auto-paper-improvement-loop | Review scored, all rounds done | Score progression | Score progression |
/run-experiment | Experiments deployed | GPU assignment + ETA | GPU assignment + ETA |
/monitor-experiment | Results collected | Results table | Results table |
/idea-discovery | Phase transitions, final report | Summary at each phase | + approve/reject at checkpoints |
/research-pipeline | Stage transitions, pipeline done | Stage summary | + approve/reject |
Not using Feishu? No problem — without ~/.claude/feishu.json, all skills behave exactly as before. Zero overhead, zero side effects.
💡 Alternative IM platforms: The push-only webhook pattern works with any service that accepts incoming webhooks (Slack, Discord, DingTalk, WeChat Work). Just change the
webhook_urland card format infeishu-notify/SKILL.md. For bidirectional support, see cc-connect (multi-platform bridge) or clawdbot-feishu.
Skills are plain Markdown files. Fork and customize:
💡 Parameter pass-through: Parameters flow down the call chain automatically. For example,
/research-pipeline "topic" — sources: zotero, arxiv download: truepassessourcesandarxiv downloadthroughidea-discoveryall the way down toresearch-lit. You can set any downstream parameter at any level — just add— key: valueto your command.research-pipeline ──→ idea-discovery ──→ research-lit ──→ experiment-bridge ──→ run-experiment ──→ auto-review-loop ──→ idea-creator ──→ novelty-check ──→ research-review
research-pipeline)| Constant | Default | Description | Pass-through |
|---|---|---|---|
AUTO_PROCEED | true | Auto-continue with top-ranked option if user doesn't respond | → idea-discovery |
ARXIV_DOWNLOAD | false | Download top arXiv PDFs after literature search | → idea-discovery → research-lit |
HUMAN_CHECKPOINT | false | When true, pause after each review round for approval | → auto-review-loop |
WANDB | false | Auto-add W&B logging to experiments | → experiment-bridge → run-experiment |
CODE_REVIEW | true | GPT-5.4 reviews experiment code before deployment | → experiment-bridge |
BASE_REPO | false | GitHub repo URL to clone as base codebase for experiments | → experiment-bridge |
COMPACT | false | Generate compact summary files for short-context models and session recovery |
Override inline: /research-pipeline "topic" — auto proceed: false, illustration: mermaid
auto-review-loop)| Constant | Default | Description |
|---|---|---|
MAX_ROUNDS | 4 | Maximum review→fix→re-review iterations |
POSITIVE_THRESHOLD | 6/10 | Score at which the loop stops (submission-ready) |
> 4 GPU-hour skip | 4h | Experiments exceeding this are flagged for manual follow-up |
idea-discovery / idea-creator)| Constant | Default | Description | Pass-through |
|---|---|---|---|
PILOT_MAX_HOURS | 2h | Skip any pilot estimated to take longer per GPU | — |
PILOT_TIMEOUT_HOURS | 3h | Hard timeout — kill runaway pilots, collect partial results | — |
MAX_PILOT_IDEAS | 3 | Maximum number of ideas to pilot in parallel | — |
MAX_TOTAL_GPU_HOURS | 8h | Total GPU budget across all pilots | — |
AUTO_PROCEED | true | Auto-continue with top-ranked option if user doesn't respond | — |
ARXIV_DOWNLOAD | false | Download top arXiv PDFs after literature search | → research-lit |
Override inline: /idea-discovery "topic" — pilot budget: 4h per idea, sources: zotero, arxiv download: true
experiment-bridge)| Constant | Default | Description |
|---|---|---|
CODE_REVIEW | true | GPT-5.4 xhigh reviews code before deployment. Catches logic bugs before wasting GPU hours |
AUTO_DEPLOY | true | Automatically deploy experiments after implementation + review. Set false to manually inspect |
SANITY_FIRST | true | Run smallest experiment first to catch setup bugs before full deployment |
MAX_PARALLEL_RUNS | 4 | Maximum experiments to deploy in parallel (limited by available GPUs) |
WANDB | false | Auto-add W&B logging. Requires wandb_project in CLAUDE.md |
BASE_REPO | false | GitHub repo URL to clone as base codebase for experiments |
Override inline: /experiment-bridge — base repo: https://github.com/org/project
research-lit)| Constant | Default | Description |
|---|---|---|
PAPER_LIBRARY | papers/, literature/ | Local directories to scan for PDFs before searching online |
MAX_LOCAL_PAPERS | 20 | Max local PDFs to scan (first 3 pages each) |
SOURCES | all | Which sources to search: zotero, obsidian, local, web, or all (comma-separated) |
ARXIV_DOWNLOAD | false | When true, download top relevant arXiv PDFs to PAPER_LIBRARY after search |
ARXIV_MAX_DOWNLOAD | 5 | Maximum number of PDFs to download when ARXIV_DOWNLOAD = true |
Override inline: /research-lit "topic" — sources: zotero, web, /research-lit "topic" — arxiv download: true, max download: 10
paper-write)| Constant | Default | Description |
|---|---|---|
DBLP_BIBTEX | true | Fetch real BibTeX from DBLP/CrossRef instead of LLM-generated entries |
TARGET_VENUE | ICLR | Target venue: ICLR, NeurIPS, ICML, CVPR, ACL, AAAI, ACM |
ANONYMOUS | true | Use anonymous author block for blind review |
MAX_PAGES | 9 | Main body page limit (excluding references) |
ILLUSTRATION | gemini | AI illustration mode: gemini (default, needs GEMINI_API_KEY), mermaid (free), or false (skip) |
Override inline: /paper-write — target venue: NeurIPS, illustration: mermaid
| Constant | Default | Description |
|---|---|---|
REVIEWER_MODEL | gpt-5.4 | OpenAI model used via Codex MCP. Also available: gpt-5.3-codex, gpt-5.2-codex, o3. See supported models for full list. |
allowed-tools — restrict or expand what each skill can doDon't have Claude / OpenAI API access? You can swap in other models — same cross-model architecture, different providers.
⭐ We strongly recommend Claude + GPT-5.4 (default setup). It's the most tested and reliable combination. Alternative setups work but may require prompt tuning.
| Executor | Reviewer | Need Claude API? | Need OpenAI API? | Guide | |
|---|---|---|---|---|---|
| Default ⭐ | Claude Opus/Sonnet | GPT-5.4 (Codex MCP) | Yes | Yes | Quick Start |
| Alt A | GLM-5 (Z.ai) | GPT-5.4 (Codex MCP) | No | Yes | Setup below |
| Alt B | GLM-5 (Z.ai) | MiniMax-M2.5 | No | No | MINIMAX_MCP_GUIDE |
| Alt C | Any CC-compatible | Any OpenAI-compatible | No | No | LLM_API_MIX_MATCH_GUIDE |
| Alt D | Kimi-K2.5 / Qwen3.5+ | GLM-5 / MiniMax-M2.5 | No | No | ALI_CODING_PLAN_GUIDE |
| Alt E 🆓 | DeepSeek-V3.1 / Qwen3-Coder | DeepSeek-R1 / Qwen3-235B | No | No | MODELSCOPE_GUIDE |
Alt C supports tested providers: GLM (Z.ai), Kimi (Moonshot), LongCat (Meituan) as executors; DeepSeek, MiniMax as reviewers. Any OpenAI-compatible API should also work via the generic llm-chat MCP server. Alt D uses Alibaba Coding Plan — one API key for both executor and reviewer, 4 models included (Kimi, Qwen, GLM, MiniMax). Alt E uses ModelScope — free (2000 calls/day), one key, no automation restrictions. Alt G keeps Codex as executor but swaps the reviewer to Claude Code CLI via the local claude-review MCP bridge, with async polling for long paper/review prompts. Alt H uses Google Antigravity as the executor with native SKILL.md support — choose Claude Opus 4.6 (Thinking) or Gemini 3.1 Pro (high) as the execution model. Alt I keeps Codex as executor, adds only a thin skills-codex-gemini-review overlay, and routes the reviewer-aware predefined skills through the local gemini-review MCP bridge with direct Gemini API by default. It is the closest Gemini analogue to the existing Codex+Claude review path, while minimizing skill changes and now also covers poster PNG review via the same bridge. Free-tier availability, rate limits, and data-use terms remain subject to Google's current policy.
* Alt G normally relies on local Codex CLI and Claude Code CLI logins. Direct API keys are optional, not required.
Only replace the executor (Claude → GLM), keep GPT-5.4 as reviewer via Codex MCP.
npm install -g @anthropic-ai/claude-code
npm install -g @openai/codex
codex setup # set model to gpt-5.4
Configure ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "your_zai_api_key",
"ANTHROPIC_BASE_URL": "https://api.z.ai/api/anthropic",
"API_TIMEOUT_MS": "3000000",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5"
},
"mcpServers": {
"codex": {
"command": "/opt/homebrew/bin/codex",
"args": ["mcp-server"]
}
}
}
Codex CLI uses your existing OPENAI_API_KEY (from ~/.codex/config.toml or environment) — no extra config needed for the reviewer side.
No Claude or OpenAI API needed. Uses a custom MiniMax MCP server instead of Codex (because MiniMax doesn't support OpenAI's Responses API). Full guide: docs/MINIMAX_MCP_GUIDE.md.
Mix and match freely using the generic llm-chat MCP server. Supports any OpenAI-compatible API as reviewer. Full guide: docs/LLM_API_MIX_MATCH_GUIDE.md.
Example combinations: GLM + DeepSeek, Kimi + MiniMax, Claude + DeepSeek, LongCat + GLM, etc.
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git
cd Auto-claude-code-research-in-sleep
cp -r skills/* ~/.claude/skills/
claude
⚠️ For non-Claude executors (GLM, Kimi, etc.): Let the model read through the project once to ensure skills are correctly parsed. This is especially important if you've rewritten skills to use a different reviewer MCP (e.g.,
mcp__llm-chat__chatinstead ofmcp__codex__codex) — the new executor needs to understand the changed tool call patterns:Read through this project and verify all skills are working: /idea-creator, /research-review, /auto-review-loop, /novelty-check, /idea-discovery, /research-pipeline, /research-lit, /run-experiment, /analyze-results, /monitor-experiment, /pixel-art
⚠️ Note: Alternative models may behave differently from Claude and GPT-5.4. You may need to tune prompt templates for best results. The core cross-model architecture remains the same.
AUTO_PROCEED (default: auto-continue; set false to always wait)/paper-plan → /paper-figure → /paper-write → /paper-compile. ICLR/NeurIPS/ICML templates, claims-evidence matrix, publication-quality figures, latexmk auto-fix. Inspired by claude-scholar, Research-Paper-Writing-Skills, baoyu-skillsgpt-5.4, also works with gpt-5.3-codex, gpt-5.2-codex, o3, etc.)/research-lit scans local papers/ and literature/ directories before external search, leveraging papers you've already read/idea-discovery orchestrates research-lit → idea-creator → novelty-check → research-review in one command, with pilot experiments on GPU/research-pipeline chains Workflow 1 (idea discovery) → implementation → Workflow 2 (auto-review-loop) end-to-end/peer-review for reviewing others' papers as a conference reviewer, with GPT-5.4 meta-review (planned; currently use /research-review with a paper PDF)~/.claude/feishu.json. Push-only needs just a webhook URL; interactive uses feishu-claude-code. Off by default — zero impact on existing workflows. See launchd/systemd for true unattended operation. Currently the orchestration layer requires an active CLI session; state files (REVIEW_STATE.json, AUTO_REVIEW.md) support resuming across sessions, but relaunch is manual (#11)paper-illustrationWORKFLOW_REPORT.md for progress tracking, team reporting, and supervisor updatesRESEARCH_BRIEF.md) as input to /research-pipeline or /idea-discovery instead of a one-line prompt. Many research directions need nuanced context (prior results, constraints, domain knowledge) that can't fit in a single sentence. The document would be parsed for problem definition, constraints, existing results, and specific requirementsDomain-specific skills welcome! The core skills cover general research workflows, but every field has its own tools and patterns. We welcome PRs that add new skills for your domain — EDA, bioinformatics, robotics, HPC, or anything else. Just add a skills/your-skill/SKILL.md and open a PR. See dse-loop for an example.
Join the WeChat group for discussion on Claude Code + AI-driven research workflows:
If you use ARIS in your research, please cite:
@misc{yang2026aris,
author = {Yang, Ruofeng and Li, Yongcan and Li, Shuai},
title = {ARIS: Fully Autonomous Research via Adversarial Multi-Agent Collaboration},
year = {2026},
organization = {GitHub},
url = {https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep},
}
ARIS is inspired by:
This project builds on and integrates with many excellent open-source projects:
Core Infrastructure
Zotero Integration (setup guide)
Obsidian Integration (setup guide)
Paper Writing Inspiration
Feishu/Lark Integration (setup guide)
Community
Special Thanks — Platform Adaptation
ARIS wouldn't run on so many platforms without these contributors:
spawn_agentSpecial Thanks — Architecture & Vision
MIT
base repo— base repo: https://github.com/org/projectgemini-review MCP bridge. CNSKILL.md support, dual model, MCP config, EN + CN. Community contribution by @PeppaPigwformula-derivation — research formula development and verification. Community contribution by @Falling-Flowerpaper-poster — Conference poster (tcbposter → A0/A1 PDF + PPTX + SVG). Venue colors, visual review, Codex review. Community contribution by @dengzhe-hou/experiment-bridge now includes GPT-5.4 cross-model code review before GPU deployment (code review: true by default). 📊 W&B fix — real wandb.Api() callsllm-chat2026-03-15 — 🐾 OpenClaw adaptation guide — use ARIS research workflows in OpenClaw without Claude Code slash skills
2026-03-15 — 📐 proof-writer — community skill for rigorous theorem proof drafting. 📚 Anti-hallucination citations — /paper-write now fetches real BibTeX from DBLP/CrossRef instead of LLM-generated entries — on by default, zero install
2026-03-14 — 📱 Feishu/Lark integration: three modes (off/push/interactive), mobile notifications for experiments, reviews, and checkpoints
2026-03-13 — 🛑 Human-in-the-loop: configurable AUTO_PROCEED checkpoints across all workflows. Full autopilot or step-by-step approval
2026-03-12 — 🔗 Zotero + Obsidian + local PDFs + arXiv/Scholar: multi-source literature search with cross-model novelty verification
2026-03-12 — 🚀 Three end-to-end workflows complete: one prompt → top-venue-style paper. /research-pipeline chains idea discovery → auto review → paper writing autonomously
2026-03-12 — 📝 /paper-writing workflow: narrative report → structured outline → figures → LaTeX → compiled PDF → 2-round auto-improvement (4/10 → 8.5/10)
code review | true | GPT-5.4 xhigh reviews experiment code before GPU deployment. Set false to skip |
wandb | false | Auto-add W&B logging to experiment scripts. Set true + configure wandb_project in CLAUDE.md. /monitor-experiment pulls training curves from W&B |
illustration | gemini | AI illustration in Workflow 3: gemini (default, needs GEMINI_API_KEY), mermaid (free), or false (skip) |
venue | ICLR | Target venue: ICLR, NeurIPS, ICML, CVPR, ACL, AAAI, ACM. Determines LaTeX style file and page limit |
base repo | false | GitHub repo URL to clone as base codebase (e.g., — base repo: https://github.com/org/project). No code? Build on top of an open-source project |
compact | false | Generate compact summary files (IDEA_CANDIDATES.md, findings.md, EXPERIMENT_LOG.md) for short-context models and session recovery |
ref paper | false | Reference paper to build on (PDF path or arXiv URL). Summarized first, then ideas extend/improve it. Combine with base repo for paper+code workflows |
/research-pipeline "your topic" — AUTO_PROCEED: false # pause at idea selection gate
/research-pipeline "your topic" — human checkpoint: true # pause after each review round to give feedback
/research-pipeline "your topic" — sources: zotero, web # only search Zotero + web (skip local PDFs)
/research-pipeline "your topic" — arxiv download: true # download top arXiv PDFs during literature survey
/research-pipeline "your topic" — AUTO_PROCEED: false, human checkpoint: true # combine options
🔀 Flexible models — default Claude × GPT-5.4, also supports GLM, MiniMax, Kimi, LongCat, DeepSeek, etc. — no Claude or OpenAI API required
🛑 Human-in-the-loop — configurable checkpoints at key decisions. AUTO_PROCEED=true for full autopilot, false to approve each step
📱 Feishu/Lark notifications — three modes: off (default, strongly recommended for most users), push-only (webhook, mobile alerts), interactive (approve/reject from Feishu). Zero impact when unconfigured
Push Only — group chat cards (experiment done, checkpoint, error, pipeline complete):
Interactive — private chat with Claude Code (approve/reject, custom instructions):
🧩 Extensible — domain-specific skills welcome! Add a SKILL.md and open a PR. See community skills like dse-loop (architecture/EDA)
/research-review/paper-illustration| Yes |
🎤 paper-slides | General | Conference talk slides (beamer → PDF + PPTX) with speaker notes, full talk script + Q&A prep. Auto slide count from talk type | Yes |
🖼️ paper-poster | General | Conference poster (article + tcbposter → A0/A1 PDF + component PPTX + SVG). Venue-specific colors, visual review loop, Codex MCP review | Yes |
📐 proof-writer | ML Theory | Rigorous theorem/lemma proof drafting — feasibility triage, dependency maps, honest blockage reports | No |
📡 comm-lit-review | Communications / Wireless | Domain-specific literature review — IEEE/ACM/ScienceDirect priority, venue tiering, PHY/MAC/transport/NTN taxonomy | No |
🏗️ dse-loop | Architecture / EDA | Autonomous design space exploration — iteratively run, analyze, and tune parameters (gem5, Yosys, etc.) | No |
🤖 idea-discovery-robot | Robotics / Embodied AI | Workflow 1 adaptation — grounds idea discovery in embodiment, benchmark, sim2real path, and real-robot safety constraints | Yes |
📐 mermaid-diagram | General | Mermaid diagrams (20+ types) — free alternative to paper-illustration, no API key needed | No |
🔢 formula-derivation | General | Research formula development — derivation, verification, and LaTeX formatting | No |
Use ARIS skills in Cursor — @-reference skills, MCP setup, workflow mapping, state file recovery across sessions |
| 🖥️ Trae Adaptation Guide | General | Use ARIS skills in Trae (ByteDance AI IDE) — EN + CN guides |
🎨 paper-illustration | General | AI-generated architecture diagrams via Gemini. Built on PaperBanana. Integrated into Workflow 3 |
🤖 skills-codex | General | Codex CLI sync pack for the main research skills, now including training-check, result-to-claim, ablation-planner, rebuttal, plus the shared-references/ support directory |
| 🎛️ auto-hparam-tuning | General | Automatic hyperparameter tuning — AI agent reads project, plans strategy, runs experiments, analyzes TensorBoard, learns from results. Hydra-based |
| 🔁 Codex+Claude Review Bridge | General | Codex executes + Claude reviews via local claude-review MCP bridge with async polling |
| Single-round deep review from external LLM (xhigh reasoning) |
| Yes |
└ 🧭 research-refine-pipeline | Refine method + plan experiments in one chain | Yes |
├ 🔬 research-refine | Problem anchor → iterative method refinement (up to 5 rounds, score ≥ 9) | Yes |
└ 🧪 experiment-plan | Claim-driven experiment roadmap with ablations, budgets, and run order | No |
| Monitor running experiments, check progress, collect results |
| No |
🔁 auto-review-loop-llm | Same as above, but uses any OpenAI-compatible API via llm-chat MCP server | No |
| Yes |
├ 🔨 paper-compile | Compile LaTeX to PDF, auto-fix errors, submission readiness checks | No |
└ 🔄 auto-paper-improvement-loop | 2-round content review + format check (4/10 → 8.5/10) | Yes |
| → all workflows |
REF_PAPER | false | Reference paper (PDF path or URL) to base ideas on. Summarized first, then used as context | → idea-discovery |
ILLUSTRATION | gemini | AI illustration: gemini (default), mermaid (free), or false (skip) | → paper-writing |
| Alt F | Codex CLI (GPT-5.4) | Codex spawn_agent (GPT-5.4) | No | Yes | skills-codex/ |
| Alt G 🆕 | Codex CLI | Claude Code CLI (claude-review MCP) | No* | No* | CODEX_CLAUDE_REVIEW_GUIDE |
| Alt H 🆕 | Antigravity (Claude Opus 4.6 / Gemini 3.1 Pro) | GPT-5.4 (Codex MCP) or any via llm-chat | No | Optional | ANTIGRAVITY_ADAPTATION |
| Alt I 🆕 | Codex CLI | Gemini direct API (gemini-review MCP) | No | No | CODEX_GEMINI_REVIEW_GUIDE |
/research-lit searches Zotero collections, reads annotations/highlights, exports BibTeX. Recommended: zotero-mcp (1.8k⭐). See setup guide/research-lit searches Obsidian vault for research notes, tagged references, wikilinks. Recommended: mcpvault (760⭐) + obsidian-skills (13.6k⭐). See setup guidellm-chat MCP server. GLM, MiniMax, Kimi, LongCat, DeepSeek all tested — no Claude or OpenAI API required/run-experiment supports code_sync: git (git push → ssh "git pull")wandb.init() + wandb.log() when wandb: true. /monitor-experiment pulls training curves/experiment-bridge/auto-review-loop